Coding LLMs - The Permanent Junior Developer
13 Nov 2025Code review is - or at least should be - an integral part of any development team’s process. A good team should also comprise developers of varying abilities and skill sets, ranging from junior to senior, from generalist to specialist. When reviewing a pull request, as much as we desire for the process to be objective and consistent, it is often the case that it matters who the author is.
The influence of experience on code review
When reviewing a junior’s code, you’ll generally pay closer attention to every detail, taking little for granted. The same goes for reviewing the code of a specialist that’s working somewhat out of their domain. However, when reviewing the code of a senior who’s in their comfort zone, it usually shows.
Developers gain a sixth sense over time (sure, I’m being a little melodramatic) particularly by reading and reviewing code, which allows them to detect when they’re reading code of this type. It all seems to fit together neatly, and you can almost feel the confidence of the author, as the solution is evidently well thought out. And this changes the way we review their code.
This is not to suggest that we should or do bindly trust senior developers - far from it - but there is an implicit level of trust during the review process that affects how we read and interpret the code.
The challenge with Large Language coding Models is that they are ostensibly good developers. They dominate coding benchmarks, are fluent in many programming languages, and produce code that often looks like it was written by a seasoned developer. However - and this is a big one - they are only good at producing code that looks right.
A deviation to explain LLM behaviour
The very nature of LLMs is to be a probabalistic token predictor. No matter the pre-training - be it self-supervised next-token prediction, Reinforcement Learning by Human Feedback, or any other paradigm, they are fundamentally built to produce text that is likely to appear in the given context, albeit stochastically. Even reasoning models* are just next- token predictors with some tricks to give the illusion of thought and rationale.
*This is true for text-based reasoning models, where the reasoning is part of the same stream of token predictions as the rest of the model outputs. Latent-space reasoning and future architectures may differ.
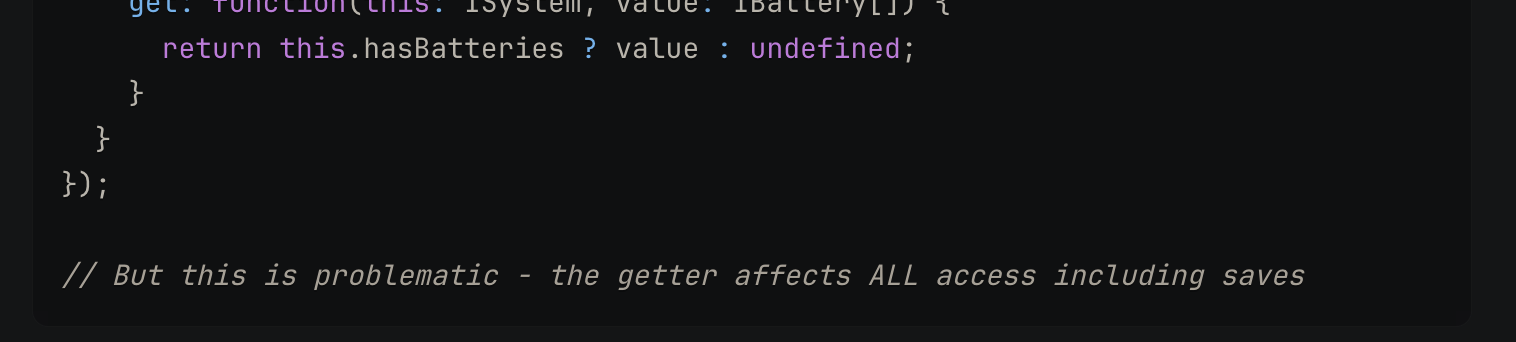
Take this Typescript example, where I asked Claude for suggestions on how to return undefined
for the MongoDB field batteries, when the boolean field hasBatteries is false, essentially masking out the field:

Although this suggestion will work when trying to read the batteries field, it will also apply while setting it.
As a result, the below may fail:
system.batteries.push('tesla-powerwall-2');
system.hasBatteries = true;
await system.save();
batteries are attempted to be set first, the getter is invoked, returning
undefined, failing the push. It introduces a subtle dependency between the two which is likely to cause unexpected behaviour/exceptions.
What’s interesting though, is what I left out of the screenshot above:
Claude knew that the code wouldn’t work as intended, but still suggested it. This is (likely) due to the stochastic
nature of LLMs.
It sampled a token sequence for the title suggesting this idea - 3. Getter in Schema... and had to
continue down that road, as it’s much more probable to continue with fleshing out the suggestion, than to stop in its
tracks and try something else.
Token sampling paths
Here’s a demonstration of how it may have come about (note that I’ll use words in place of tokens for clarity):
- The probability of suggesting the starting sequence
3.is very high.- The suggestion is part of a list, and we’re quite clearly up to the next number (3).
- This word is selected, and added to the context for the next token prediction.
- The probability of the next word being
Custom(as in, to begin suggesting a ‘Custom Document class’) is quite high, let’s say 75%.- This is a good suggestion, and something often performed with (Mongoose).
- The probability of this word instead being
Getteris reasonably high, but lower, say 20%.- Getters are often used in schema definitions to manipulate how data is accessed, but not an appropriate choice here.
- The remaining 5% of probability is spread across all other possible words.
As the model randomly samples from this distribution, it’s more likely to pick Custom, it may pick Getter instead
by pure chance (20% of the time). Once that word has been selected, the next word’s probabilities are re-evaluated in
context of the newly selected word, and the process continues. It is extremely unlikely that once the model has started
down the ‘Getter’ path, it will produce a suggestion that contradicts it.
Thus, after the model fleshed out its entire suggestion, it appended a caveat that the code may not work as intended. This is fine in a conversation such as the one I was having with Claude, but when running code generation in an IDE or similar, the structure of code means that one almost never encounters such post-hoc caveats. The model may thus produce code that looks correct, but is fundamentally flawed, simply due to the randomness of token sampling.
This explanation is being generous, as the most-probable token path may still lead to incorrect code, but the stochastic nature of LLMs amplifies this effect.
The permanent junior developer
What this means for a code reviewer, is that you can never gain the same level of implicit trust in LLM-generated code, as there is always a chance that the code was the result of a less-likely token sampling path. In addition, the quality of code from section to section may vary wildly, as there are many forks in the road during token sampling, where the probability distribution may be quite flat between multiple options.
LLMs produce code that often looks very confident and well-structured, giving the impression of seniority and experience. This can lead to reviewers lowering their guard, and building an implicit trust in the code.
Instead, reviewers must approach LLM-generated code with the same level of scrutiny as they would for a junior developer. Every line must be examined, assumptions questioned, and edge cases considered. This is not to mention the business-domain knowledge that LLMs lack. Human developers live in the world they code for, they (should) understand the context of the code they’re writing, with a good understanding of the business domain. Codebases typically don’t contain all of the context required to solve business problems, as they often live outside of the code itself - conversations with stakeholders, company culture, user feedback, documentation, emails, etc.
We all know that reading code is harder than writing it (related - Kernighan’s Law), but by utilising LLMs for code generation, we shift the burden of correctness from the authoring phase to the review phase. Reviewers must be aware of this trade-off, and account for this in their processes.
How we do so, is an open question.